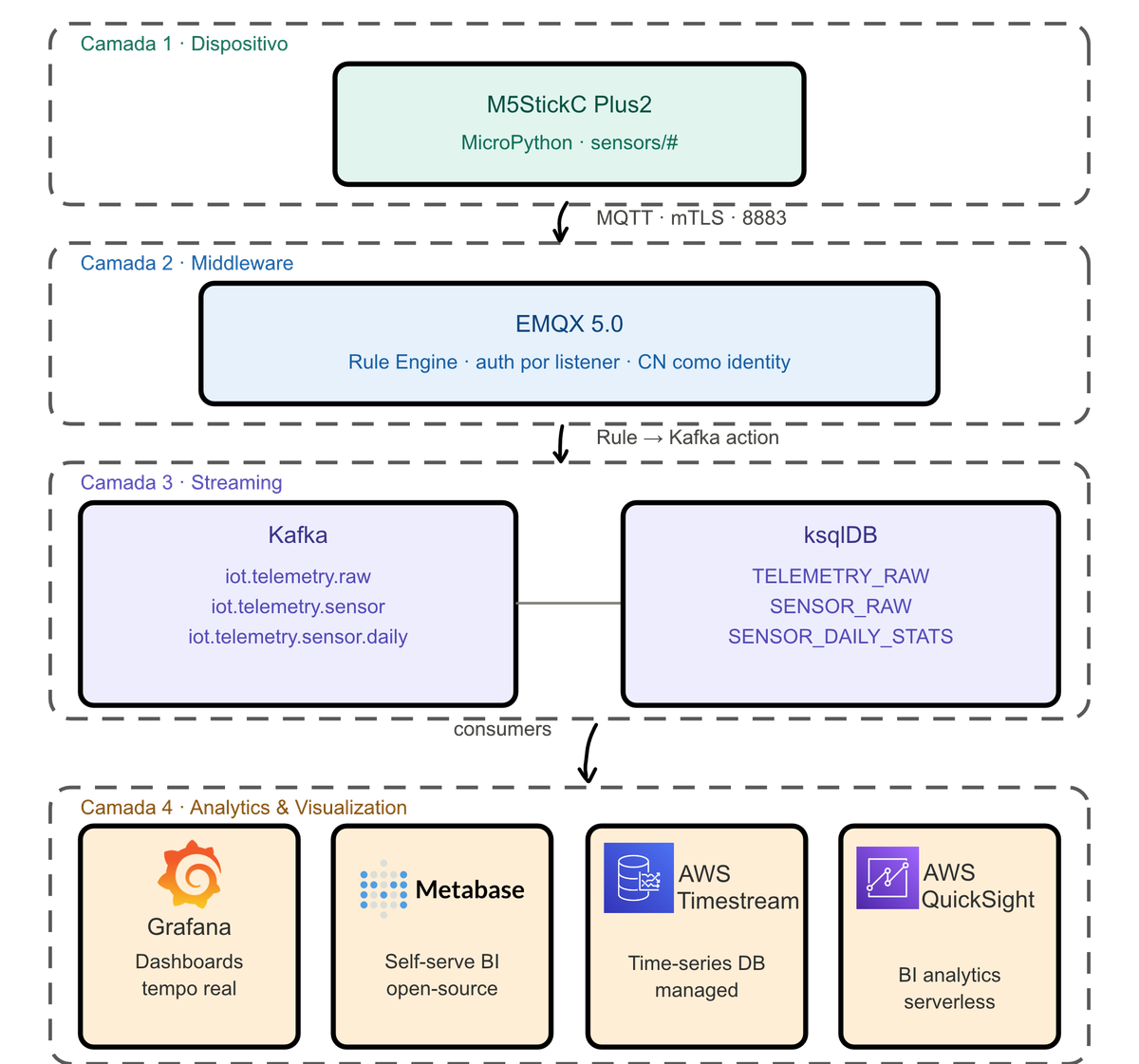
Stack IoT MQTT mTLS → Kafka → ksqlDB
Por que on Premisse?
A maioria dos tutoriais de IoT começa com AWS IoT Core, Azure IoT Hub ou algum broker SaaS. São boas opções, hoje vou mostrar um arquitetura para empresas, como Operadoras, ou Enterprises que preferem rodar suas próprias cloud privadas. Ou em qualquer cloud em containers.
Esta stack foi construída com as seguintes premissas:
- Controle total sobre os dados
- mTLS obrigatório, nenhum dispositivo sem certificado válido consegue conectar
- Pipeline de streaming
- Custo operacional próximo de zero.
- Para ser justo neste item, O custo aqui são seus próprios servidores e seus analistas de TI. Analistas estes que precisaria ter do mesmo jeito para operar soluções em nuvens.
Uma arquitetura que faria sentido numa planta industrial, numa rede privativa ou isolada da internet.
Visão geral da arquitetura

Cada camada tem responsabilidade única.
- O EMQX não conhece o Kafka diretamente, ele autentica e controla as chaves mTLS dos dispositivos, valida quem pode postar em qual tópico e dispara uma rule de transporte de dados. Aqui ele faz o papel de Midleware/segunda camada citado neste post aqui
- O Kafka não conhece o dispositivo, ele só recebe mensagens com um tópico e um payload.
Camada 1: O dispositivo - M5StickC Plus2 com MicroPython
O cliente é um M5StickC Plus2 rodando MicroPython. Ele coleta dados de sensores e publica no tópico sensors/device-001 a cada intervalo configurável.
A conexão usa mTLS: o dispositivo carrega três arquivos no filesystem interno, ca.pem, cert.pem e key.pem. Sem esses certificados, a conexão é recusada na camada TLS antes mesmo de chegar ao MQTT.
MQTT_HOST = "mqtt.mfs.eng.br"
MQTT_PORT = 8883
MQTT_TOPIC = "sensors/device-001"
DIR_CERTS = "certificate"
FILE_CA = "ca.pem"
FILE_CERT = "cert.pem"
FILE_KEY = "key.pem"O payload publicado pelo dispositivo é um JSON com campos de sistema, rede, ambiente e identidade do hardware:
{
"clientid": "device-001",
"host": "189.37.74.112:18983",
"mqtt_topic": "sensors/device-001",
"ts": 1774877350907,
"pub_rec_date": 1774877350907,
"payload": {
"timestamp": "2026-03-30T13:29:10",
"system": {
"send_interval_seconds": 60,
"send_count": 647,
"is_charging": true,
"client_id": "device-001",
"battery_v": 4.246,
"battery_pct": 100
},
"network": {
"ssid": "MinhaRede",
"rssi": -39,
"mac": "00:4B:12:C4:B8:0C",
"ip": "192.168.68.107"
},
"env": {
"temperature": 26.2,
"pressure": 911.22,
"humidity": 58.18,
"altitude_est": 886.4
},
"device": {
"unique_id": "004B12C4B80C",
"micropython_version": "1.25.0",
"machine": "M5STACK StickC PLUS2 with ESP32(SPIRAM)",
"cpu_freq_mhz": 240,
"chip": "esp32"
}
}
}Depois eu faço um novo post explicando sobre certificados, mTLS e como gerar eles do lado do dispositivo e do servidor.
Camada 2: EMQX 5.0
Por que EMQX?
O EMQX 5 tem uma feature nativa que eu gosto muito: autenticação isolada por listener. Isso significa que você pode ter na mesma instância:
- Porta 8883: aceita apenas certificado de cliente (mTLS), sem usuário/senha
- Porta 1883: aceita apenas usuário/senha, sem TLS
- Porta 8083: WebSocket com usuário/senha
Cada listener tem sua própria cadeia de autenticação. Um dispositivo sem certificado não consegue conectar na 8883, mesmo que apresente credenciais válidas.
Configuração dos listener mTLS
# mTLS — dispositivos IoT
listeners.ssl.default {
bind = "0.0.0.0:8883"
enable_authn = false
ssl_options {
cacertfile = "etc/certs/rootCA.crt"
certfile = "etc/certs/server.crt"
keyfile = "etc/certs/server.key"
verify = verify_peer
fail_if_no_peer_cert = true
}
}
mqtt.peer_cert_as_clientid = cn
mqtt.peer_cert_as_username = cnUsando o CN do certificado como identidade
Uma decisão de design importante: o EMQX pode extrair o Common Name do certificado de cliente e usá-lo como clientid e username automaticamente.
mqtt.peer_cert_as_clientid = cn
mqtt.peer_cert_as_username = cnIsso significa que a identidade do dispositivo é o próprio certificado, não uma senha que pode vazar. O CN device-001 vira automaticamente o clientid na sessão MQTT.
Camada 3: Kafka + ksqlDB
Kafka em KRaft
O Kafka roda sem Zookeeper usando KRaft, o modo nativo de consenso do Kafka desde a versão 3. Menos um processo para gerenciar, menos uma fonte de falha.
A rule SQL no EMQX seleciona os campos do payload e encaminha para a action Kafka:
SELECT
timestamp as ts,
clientid,
peername as host,
topic as mqtt_topic,
publish_received_at as pub_rec_date,
json_decode(payload) as p
FROM
"sensors/+"ksqlDB — Stream de entrada (TELEMETRY_RAW)
O stream de entrada mapeia o tópico iot.telemetry.raw com o schema completo do payload. Um aprendizado importante na prática: dentro de STRUCT<> o ksqlDB não aceita backticks nem INTEGER, use INT. A palavra timestamp funciona normalmente dentro do STRUCT, ao contrário do que se esperaria.
CREATE STREAM TELEMETRY_RAW (
clientid VARCHAR,
host VARCHAR,
mqtt_topic VARCHAR,
ts BIGINT,
pub_rec_date BIGINT,
payload STRUCT<
timestamp VARCHAR,
system STRUCT<
send_interval_seconds INT,
send_count INT,
is_charging BOOLEAN,
client_id VARCHAR,
battery_v DOUBLE,
battery_pct INT
>,
network STRUCT<
ssid VARCHAR,
rssi INT,
mac VARCHAR,
ip VARCHAR
>,
env STRUCT<
temperature DOUBLE,
pressure DOUBLE,
humidity DOUBLE,
altitude_est DOUBLE
>,
device STRUCT<
unique_id VARCHAR,
ram_free_b BIGINT,
ram_alloc_b BIGINT,
micropython_version VARCHAR,
machine VARCHAR,
flash_size_kb INT,
firmware VARCHAR,
cpu_freq_mhz INT,
chip VARCHAR
>
>
) WITH (
KAFKA_TOPIC = 'iot.telemetry.raw',
VALUE_FORMAT = 'JSON',
TIMESTAMP = 'ts'
);ksqlDB — Stream derivado flat (SENSOR_RAW)
A partir do stream raw, criamos um stream flat com apenas as variáveis de ambiente, RSSI e identidade do dispositivo. O clientid vira device e tudo fica no mesmo nível, sem aninhamento.
CREATE STREAM SENSOR_RAW
WITH (
KAFKA_TOPIC = 'iot.telemetry.sensor',
VALUE_FORMAT = 'JSON',
PARTITIONS = 6
) AS
SELECT
clientid AS device,
ts,
payload->network->rssi AS rssi,
payload->env->temperature AS temperature,
payload->env->pressure AS pressure,
payload->env->humidity AS humidity,
payload->env->altitude_est AS altitude_est
FROM TELEMETRY_RAW
EMIT CHANGES;O resultado no tópico iot.telemetry.sensor é um JSON plano, fácil de consumir por qualquer sink:
{
"DEVICE": "device-001",
"TS": 1774877350907,
"RSSI": -39,
"TEMPERATURE": 26.2,
"PRESSURE": 911.22,
"HUMIDITY": 58.18,
"ALTITUDE_EST": 886.4
}ksqlDB — Tabela de estatísticas diárias (SENSOR_DAILY_STATS)
Uma tabela com janela tumbling de 1 dia agrega mínimo, máximo e média de todas as variáveis por dispositivo. A chave da tabela é composta por device + janela, então cada dispositivo tem exatamente um registro por dia.
CREATE TABLE SENSOR_DAILY_STATS
WITH (
KAFKA_TOPIC = 'iot.telemetry.sensor.daily',
VALUE_FORMAT = 'JSON',
PARTITIONS = 6
) AS
SELECT
device,
WINDOWSTART AS window_start,
WINDOWEND AS window_end,
COUNT(*) AS total_records,
MIN(temperature) AS temperature_min,
MAX(temperature) AS temperature_max,
ROUND(AVG(temperature), 2) AS temperature_avg,
MIN(pressure) AS pressure_min,
MAX(pressure) AS pressure_max,
ROUND(AVG(pressure), 2) AS pressure_avg,
MIN(humidity) AS humidity_min,
MAX(humidity) AS humidity_max,
ROUND(AVG(humidity), 2) AS humidity_avg,
MIN(altitude_est) AS altitude_min,
MAX(altitude_est) AS altitude_max,
ROUND(AVG(altitude_est), 2) AS altitude_avg,
MIN(rssi) AS rssi_min,
MAX(rssi) AS rssi_max,
ROUND(AVG(rssi), 2) AS rssi_avg
FROM SENSOR_RAW
WINDOW TUMBLING (SIZE 1 DAY)
GROUP BY device
EMIT CHANGES;Para consultar as estatísticas do dia de um dispositivo específico:
SELECT
device,
TIMESTAMPTOSTRING(window_start, 'yyyy-MM-dd') AS dia,
temperature_min, temperature_max, temperature_avg,
humidity_min, humidity_max, humidity_avg,
pressure_min, pressure_max, pressure_avg,
rssi_min, rssi_max, rssi_avg
FROM SENSOR_DAILY_STATS
WHERE device = 'device-001'
EMIT CHANGES;O resultado é um pipeline reativo: quando o M5Stick publica, o dado atravessa EMQX → Kafka → ksqlDB em menos de um segundo, e as estatísticas diárias são atualizadas em tempo real.
Decisões de design e trade-offs
mTLS em vez de usuário/senha nos dispositivos: Certificados não podem ser adivinhados por força bruta. Um dispositivo comprometido pode ter seu certificado revogado na CA sem afetar os demais.
Kafka em vez de gravar direto no banco: O banco é um sink, não a fonte da verdade. Com Kafka no meio, é possível adicionar novos consumidores sem alterar o produtor.
ksqlDB em vez de consumidores customizados: Para agregações e transformações simples, SQL é suficiente e mais legível do que código Python ou Java.
Streams em camadas: O TELEMETRY_RAW preserva o schema completo do dispositivo. O SENSOR_RAW é o stream de trabalho, flat e leve. A tabela SENSOR_DAILY_STATS entrega agregações prontas sem nenhuma consulta adicional.
Conclusão
Esta stack não é a mais simples de configurar. Mas é a mais honesta para se rodar on Premisse.
O M5Stick poderia ser qualquer dispositivo IoT com suporte a mTLS.
O EMQX escala para milhões de conexões simultâneas mantendo a mesma configuração.
O Kafka absorve picos sem perda, desacopla a arquitetura entre escrita e leitura.
O ksqlDB processa em tempo real sem infraestrutura adicional.